随着人工智能技术的快速发展,大语言模型在自然科学研究和试验发展领域展现出巨大潜力。清华大学张强教授团队近期在储能研究中创新性地引入大语言模型技术,为这一传统研究领域注入了新的活力。
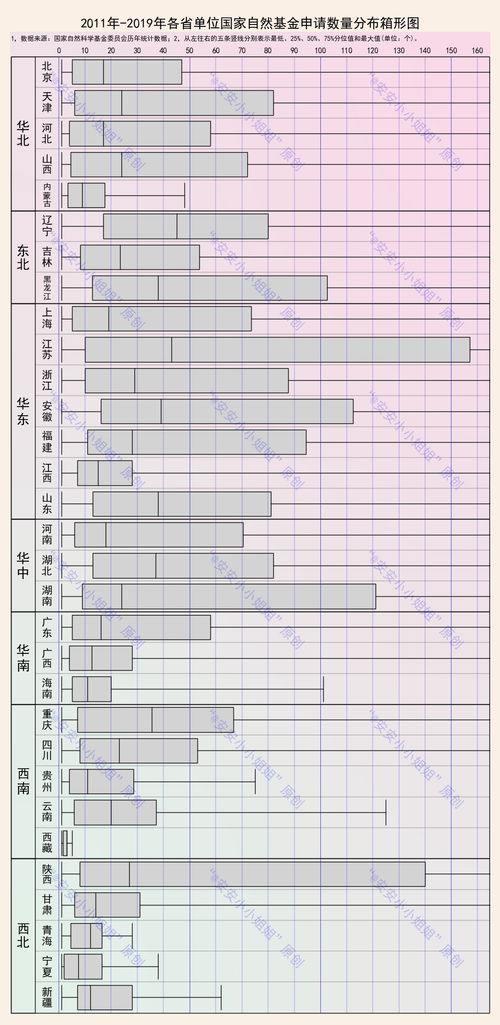
在储能材料研究方面,研究团队利用大语言模型强大的自然语言处理能力,对海量科学文献进行深度挖掘和分析。通过对数百万篇相关研究论文的学习,模型能够准确识别材料特性与性能之间的复杂关联,为新型储能材料的发现提供了重要线索。这种基于大数据的方法显著提升了材料筛选的效率,使得原本需要数月甚至数年的材料预筛选工作可在数周内完成。
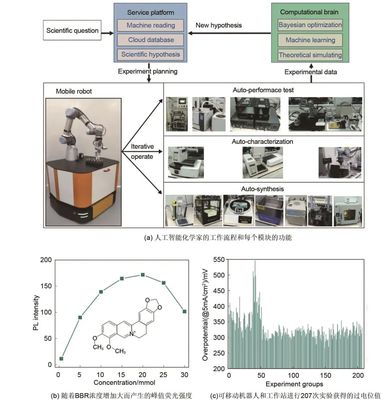
在储能系统优化设计领域,研究团队开发了专门面向储能系统的大语言模型应用框架。该框架能够理解复杂的物理化学方程和工程设计规范,为研究人员提供智能化的设计方案建议。通过自然语言交互,研究人员可以快速获取系统参数优化建议、故障诊断分析和性能预测等专业支持,大大提升了研发效率。
在实验数据分析和知识发现方面,大语言模型展现出独特优势。研究团队构建的专用模型能够理解实验数据的语义含义,自动生成实验报告,并提出可能的研究方向。更重要的是,模型能够从分散的研究成果中发现潜在的知识关联,促进跨学科知识的融合创新。
值得注意的是,团队在应用过程中也面临诸多挑战,包括专业知识表示的准确性、模型推理的可解释性,以及科学发现验证的可靠性等。为此,研究团队开发了专门的验证机制和交互式研究平台,确保模型输出结果的科学性和实用性。
张强教授团队将继续深化大语言模型在储能研究中的应用,重点推进模型在材料设计、系统优化和跨尺度模拟等方面的能力建设。这一研究方向不仅为储能技术的发展提供了新的方法论支持,也为人工智能在自然科学研究和试验发展中的应用开辟了新的路径。
大语言模型与储能研究的深度融合,标志着人工智能正成为推动自然科学进步的重要力量。随着技术的不断完善和应用场景的拓展,这种创新研究模式有望在更多科学领域发挥重要作用,为人类应对能源挑战提供更强大的技术支撑。